
What is ENGROSS?

Twitter data collection, advanced NLP analysis, and visualizations for valuable insights.
Data Collection
Our product employs a combination of data collection methods, including scraping tweets and using the Twitter API, to gather large volumes of relevant Twitter data quickly and efficiently.
Prescriptive and Descriptive Analysis
Our product uses natural language processing (NLP) techniques, including Bert embedding and topic modeling, to extract insights from the Twitter data we collect and identify patterns and trends in the data.
Visualizations
Our product showcases the insights gained from the Twitter data analysis in a range of visual formats, including graphs and charts. By presenting the results in an easily understandable way, we make our research accessible to a broad audience.
Consequuntur inventore voluptates consequatur aut vel et. Eos doloribus expedita. Sapiente atque consequatur minima nihil quae aspernatur quo suscipit voluptatem.
Repudiandae rerum velit modi et officia quasi facilis
Laborum omnis voluptates voluptas qui sit aliquam blanditiis. Sapiente minima commodi dolorum non eveniet magni quaerat nemo et.
Incidunt non veritatis illum ea ut nisi
Non quod totam minus repellendus autem sint velit. Rerum debitis facere soluta tenetur. Iure molestiae assumenda sunt qui inventore eligendi voluptates nisi at. Dolorem quo tempora. Quia et perferendis.
Omnis ab quia nemo dignissimos rem eum quos..
Eius alias aut cupiditate. Dolor voluptates animi ut blanditiis quos nam. Magnam officia aut ut alias quo explicabo ullam esse. Sunt magnam et dolorem eaque magnam odit enim quaerat. Vero error error voluptatem eum.
Consequuntur inventore voluptates consequatur aut vel et. Eos doloribus expedita. Sapiente atque consequatur minima nihil quae aspernatur quo suscipit voluptatem.
Repudiandae rerum velit modi et officia quasi facilis
Laborum omnis voluptates voluptas qui sit aliquam blanditiis. Sapiente minima commodi dolorum non eveniet magni quaerat nemo et.
Incidunt non veritatis illum ea ut nisi
Non quod totam minus repellendus autem sint velit. Rerum debitis facere soluta tenetur. Iure molestiae assumenda sunt qui inventore eligendi voluptates nisi at. Dolorem quo tempora. Quia et perferendis.
Omnis ab quia nemo dignissimos rem eum quos..
Eius alias aut cupiditate. Dolor voluptates animi ut blanditiis quos nam. Magnam officia aut ut alias quo explicabo ullam esse. Sunt magnam et dolorem eaque magnam odit enim quaerat. Vero error error voluptatem eum.
Features
Project Creation
Our project provides a user-friendly interface for users to create projects and specify the parameters of the data collection process.
- You can choose to include retweet, like, reply and quote information into the collected data.
- You can specify date and location of the tweet that will be crawled.
- You can adjust the range of the data collection based on your research needs.
Once you specify the parameters of the data collection process, you can give certain keywords to the data collection process. You can also upload a text corpus and let our keyword extraction service, which you can adjust the extraction method, to provide possible keywords for you to select. The data collection process will then crawl tweets that contain the keywords you specified. Once you are done with the preperations, you can send a project creation request for the admins and moderators to view and approve.
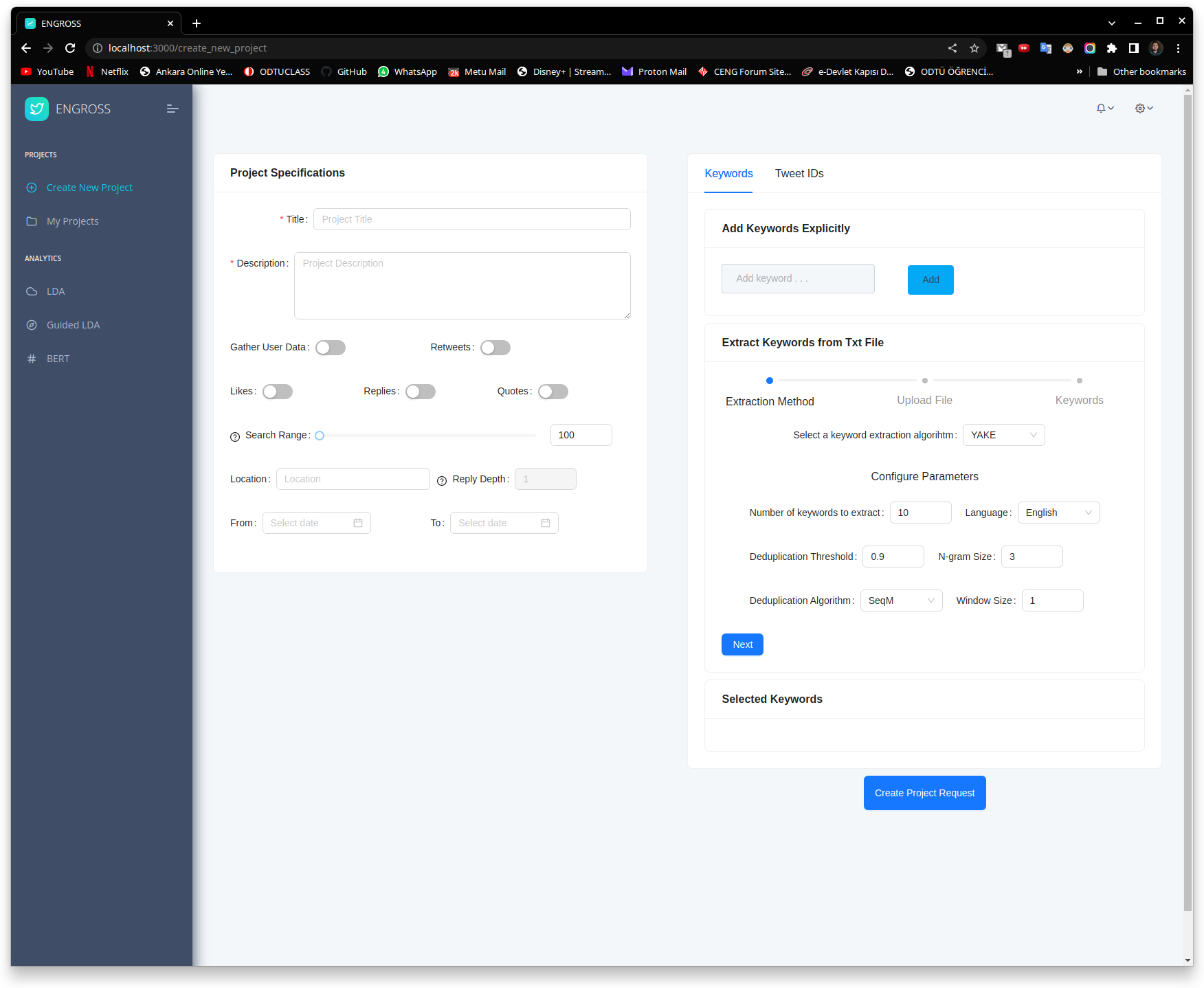
Monitoring
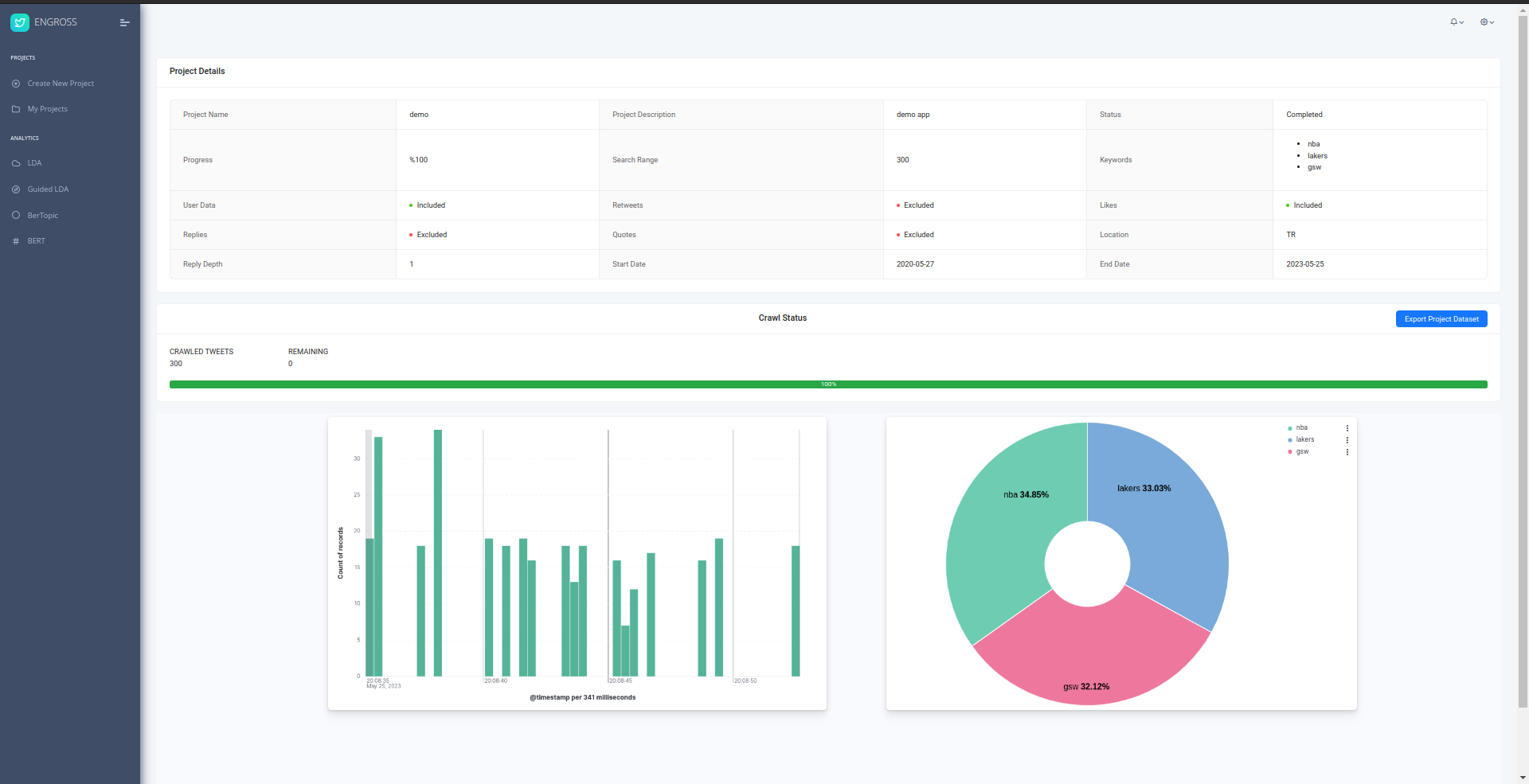
Once you created your project, you can view the status of your crawling process, edit the parameters, and fine-tune the details of your project as needed.
- You can view how many tweets have been crawled and how many tweets are left to be crawled.
- You can stop the crawling process, if you think you have enough data.
- You can change the parameters of the crawling process, such as the date and location.
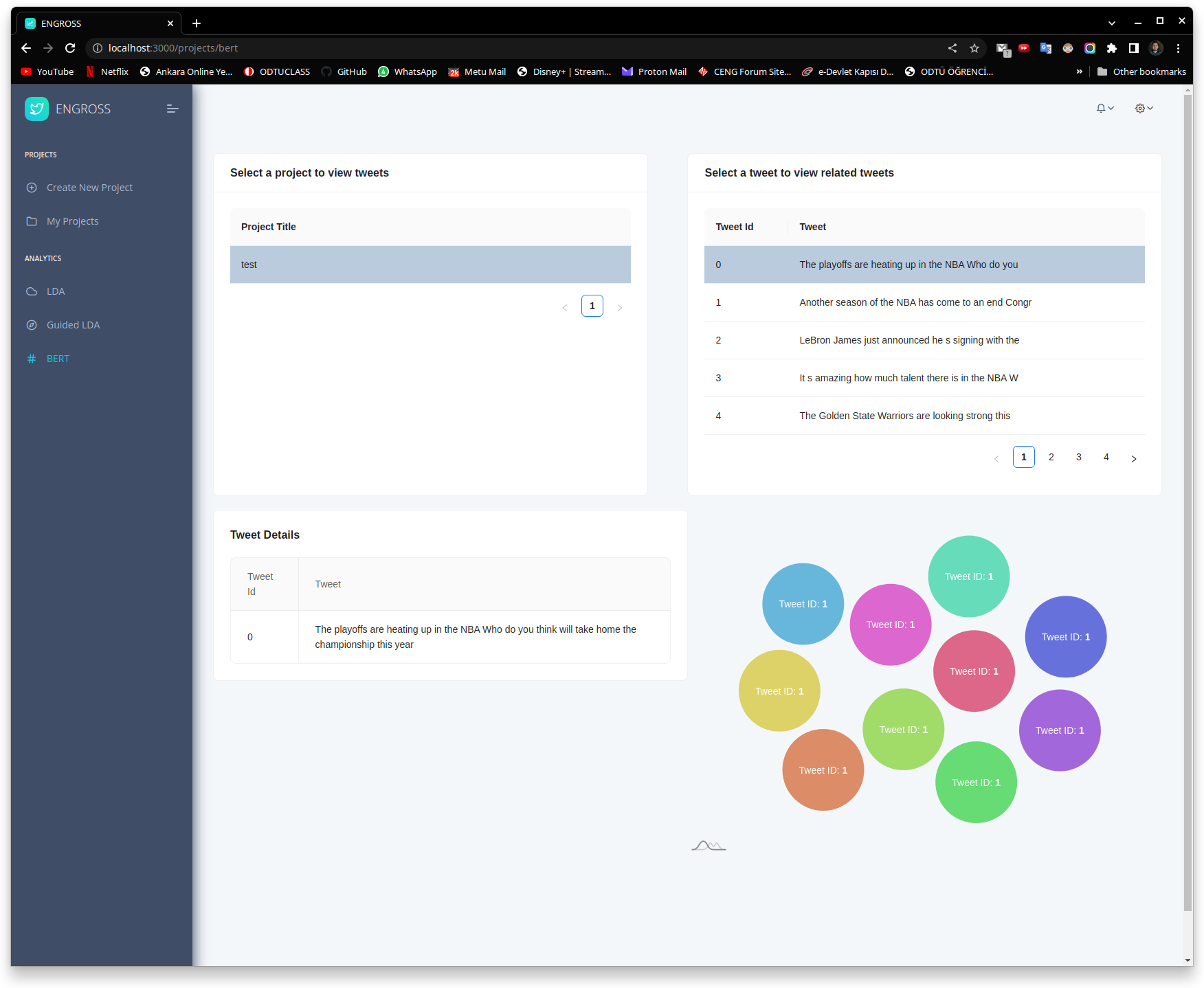
Word Embedding
Word embedding is a fundamental technique in natural language processing that enables the conversion of textual data into a numerical representation. This approach allows us to perform various operations, such as text classification, clustering, and sentiment analysis, on textual data.
- In our project, we are exploring several popular word embedding algorithms, such as BERT, GloVe, RoBERTa, and word2vec, to analyze Twitter data. Each of these algorithms has its strengths and weaknesses, and we will experiment with them to determine which is best suited for our specific use case.
- Once we have selected the appropriate word embedding algorithm, we will apply it to the tweets we have gathered through our tweet crawler. This process involves converting the textual data of each tweet into a numerical representation using the selected algorithm. These numerical representations are known as embeddings, which capture the semantic meaning of each word in the tweet.
- These embeddings allows our project to find closest related tweets by calculating cosine similaritiesThese embeddings allows our project to find closest related tweets by calculating cosine similarities.
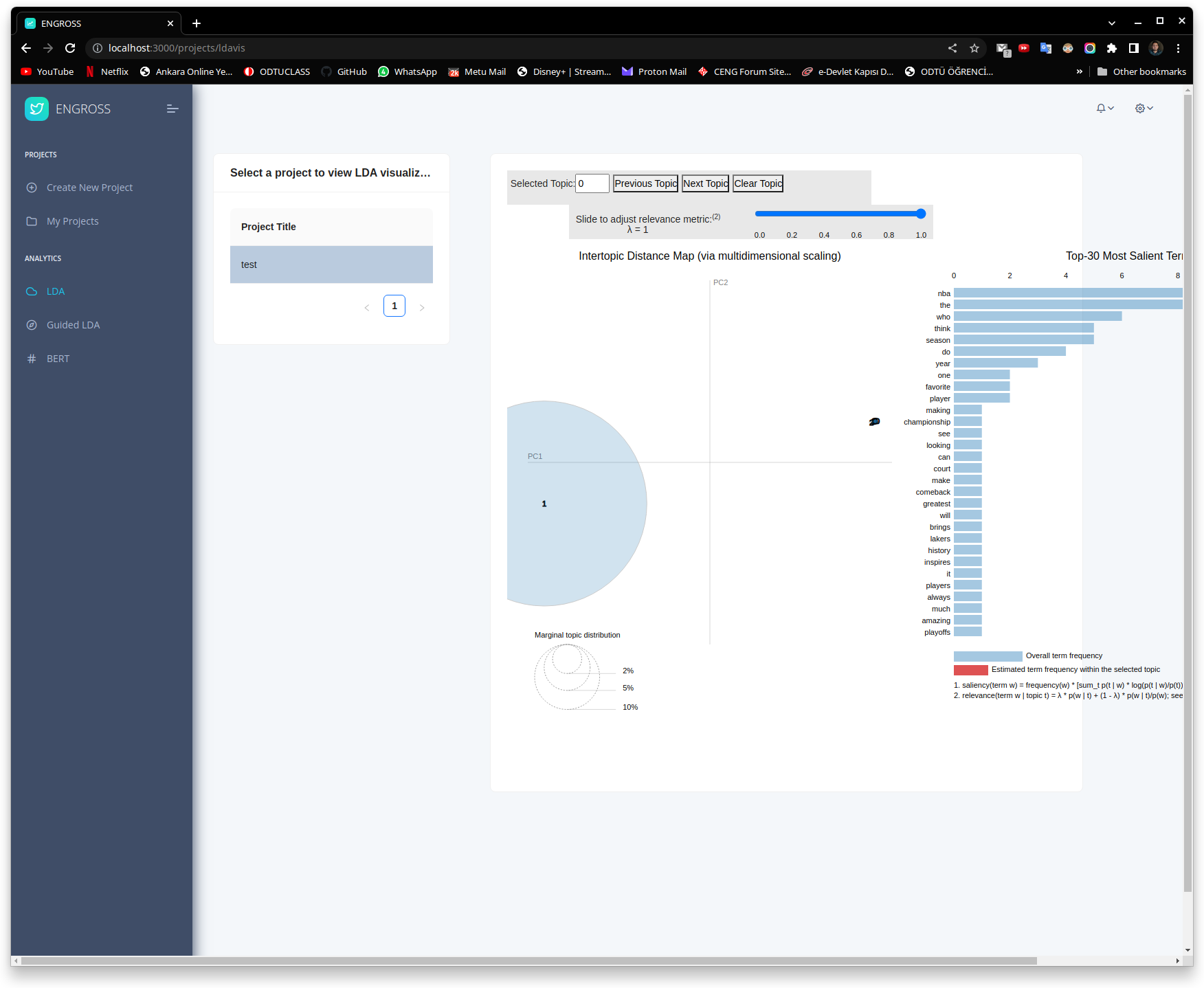
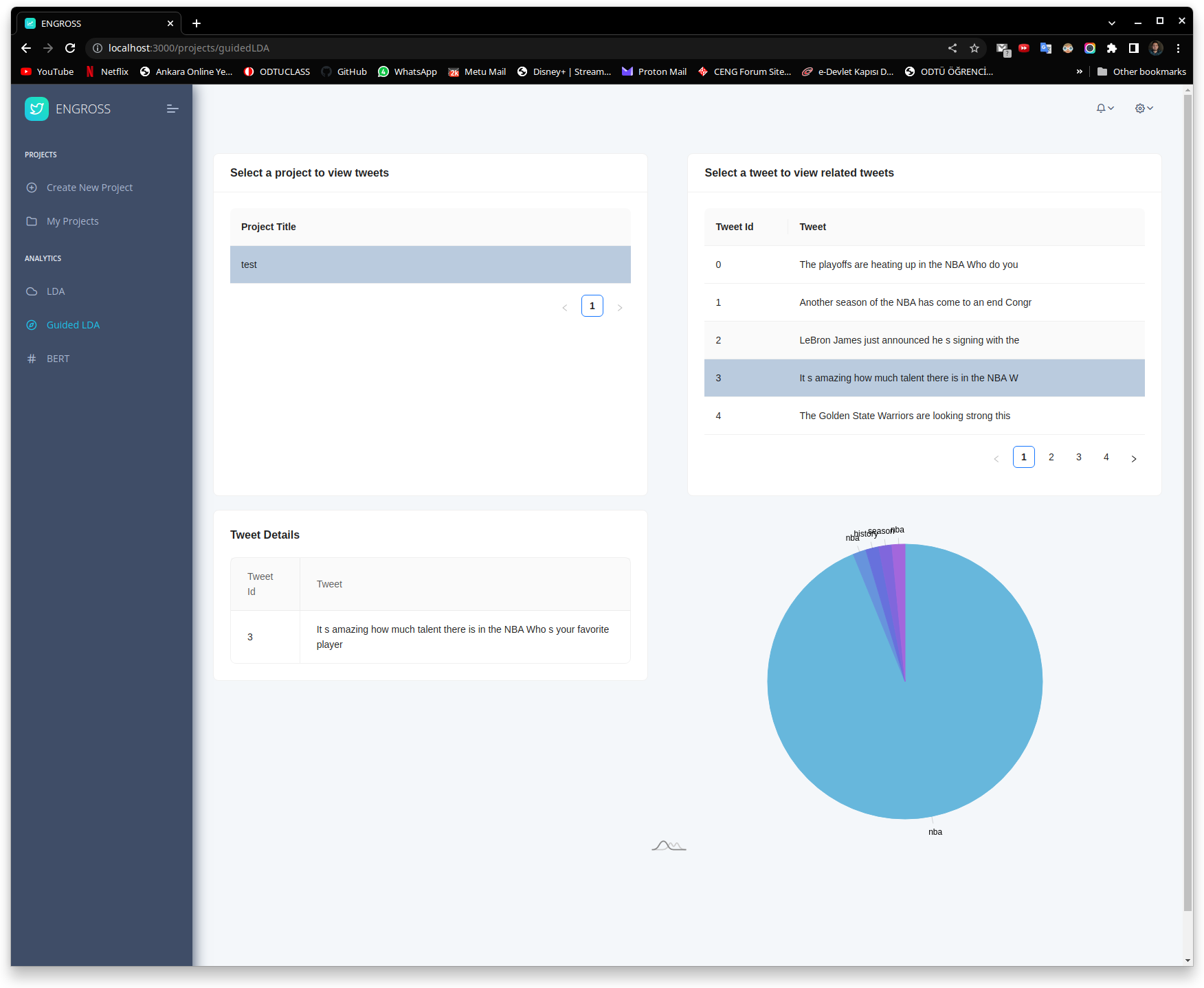
Topic Modelling
Our software uses sophisticated machine learning algorithms, such as Latent Dirichlet Allocation (LDA), to analyze the text of each crawled tweet and identify the most relevant topics. The identified topics can be presented to users in a variety of ways, such as a list or word cloud, taking it easy to understand and interpret the insights gained from the data.
- Our software is designed to be user-friendly and intuitive, with a simple and easy-to-use interface.
- With the interactive capabilities of the interface, you can easily zoom in on specific topics, explore word frequency distributions, and even view topic similarity maps.
- In addition, our platform provides you with a range of customization options, so you can tailor your visualizations to suit your needs. You can adjust the color scheme, change the font size, and even customize the tooltip content.
Data Labeling
In our project, we can use AI-based data labeling techniques to label our Twitter data. We use natural language processing (NLP) models to automatically classify tweets into different categories based on their content.
- Once our data is labeled, we can visualize it using tools like Kibana. Kibana provides powerful data visualization capabilities that allow us to create interactive dashboards that combine charts, maps, and filters to display the full picture of our data. We can use Kibana to explore our labeled data, identify patterns and trends, and gain insights into user behavior and engagement.
- In addition to data visualization, Kibana also provides advanced logging and time-series analytics capabilities, which can be used to monitor our application's performance and identify issues in real-time. By combining data labeling, visualization, and advanced analytics techniques, we can gain valuable insights into our Twitter data, enabling us to make more informed decisions and improve our project's overall performance.
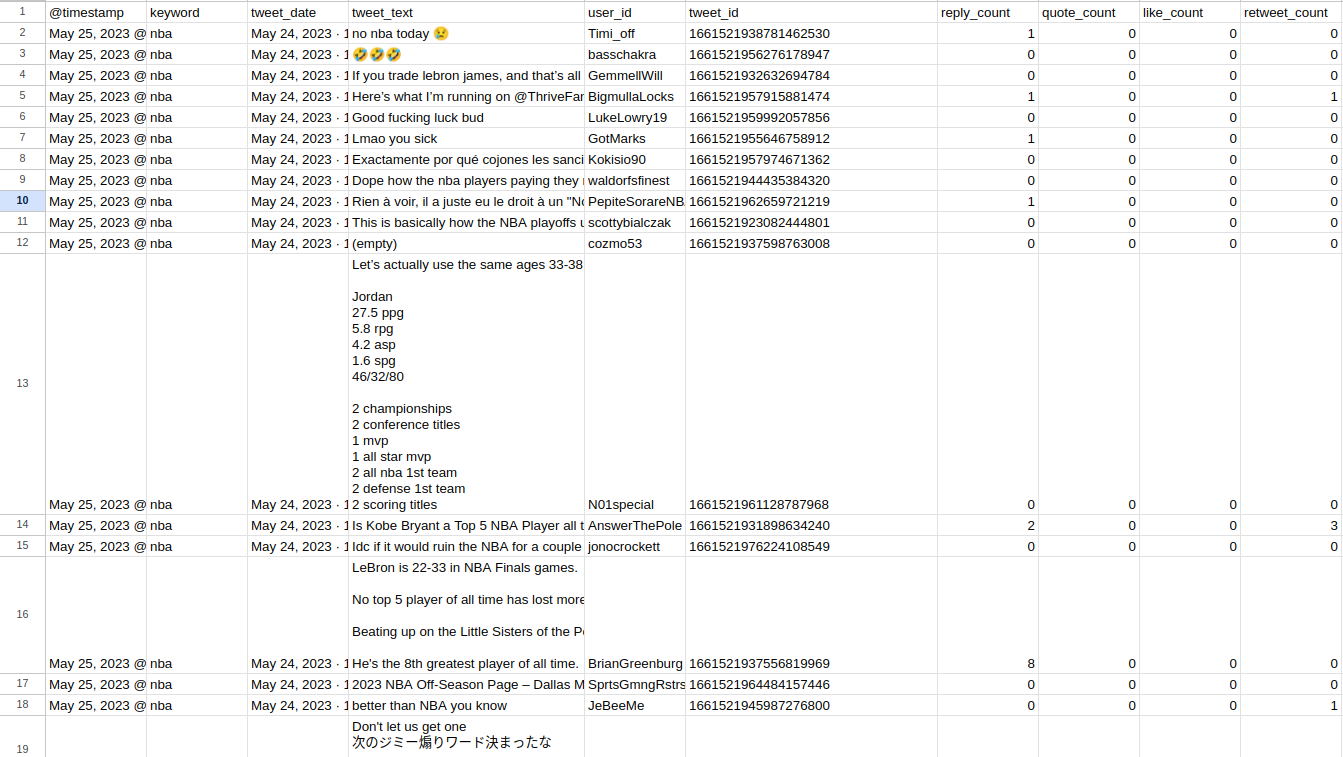
Export
Users can export their tweet dataset as a comprehensive CSV file. Each entry in the file includes tweet information, vector representation, and BERT embeddings, providing users with a wealth of data for analysis and further processing.
- The CSV file export feature allows users to conveniently retrieve their entire tweet dataset, enabling seamless integration with external tools and platforms.
- Each entry in the exported file includes essential tweet details such as timestamp, user handle, tweet text, along with vector representation and BERT embeddings for comprehensive analysis.
Our Team

İsmail Hakkı Toroslu
Supervisor
Yusuf Mücahit Çetinkaya
Supervisor
Necat Kılıçarslan
Backend Developer
Ali Kömürcü
DevOps Engineer
Emre Can Koparal
Python Developer
Mustafa Aydoğdu
Data Engineer
Ahmet Boran Özüm
Frontend DeveloperSoftware Stack







